
Es gibt Fragen, die sich erst dann als wirklich komplex entpuppen, wenn man anfängt, sie ernsthaft zu stellen. Die Frage, wie man Künstliche Intelligenz testet, gehört fraglos dazu. Und wer jetzt denkt: „Na ja, man schreibt halt ein paar Testfälle, gibt dem Ding ein paar Eingaben und schaut, was rauskommt“ – dem sei herzlich willkommen in der vollständig anderen Realität gesagt. Denn was sich auf den ersten Blick nach methodischer Hausmannskost anhört, entpuppt sich bei näherer Betrachtung als epistemologisches Minenfeld mit gelegentlichen Showeinlagen aus dem Bereich funktionaler Sicherheit. Wovon sprechen wir also? KI als Testobjekt oder Testumgebung?
Die Grundfrage ist deceptively simple, wie der Angelsächsische so schön sagt: Reden wir von KI als Testobjekt – also von dem Ding, das wir prüfen wollen – oder von KI als Testsystem – also von dem Ding, das prüft? Diese Unterscheidung klingt akademisch, ist aber in der Praxis der Unterschied zwischen „leicht kompliziert“ und „wir brauchen einen Anwalt, einen Philosophen und einen Notfallpsychologen“.
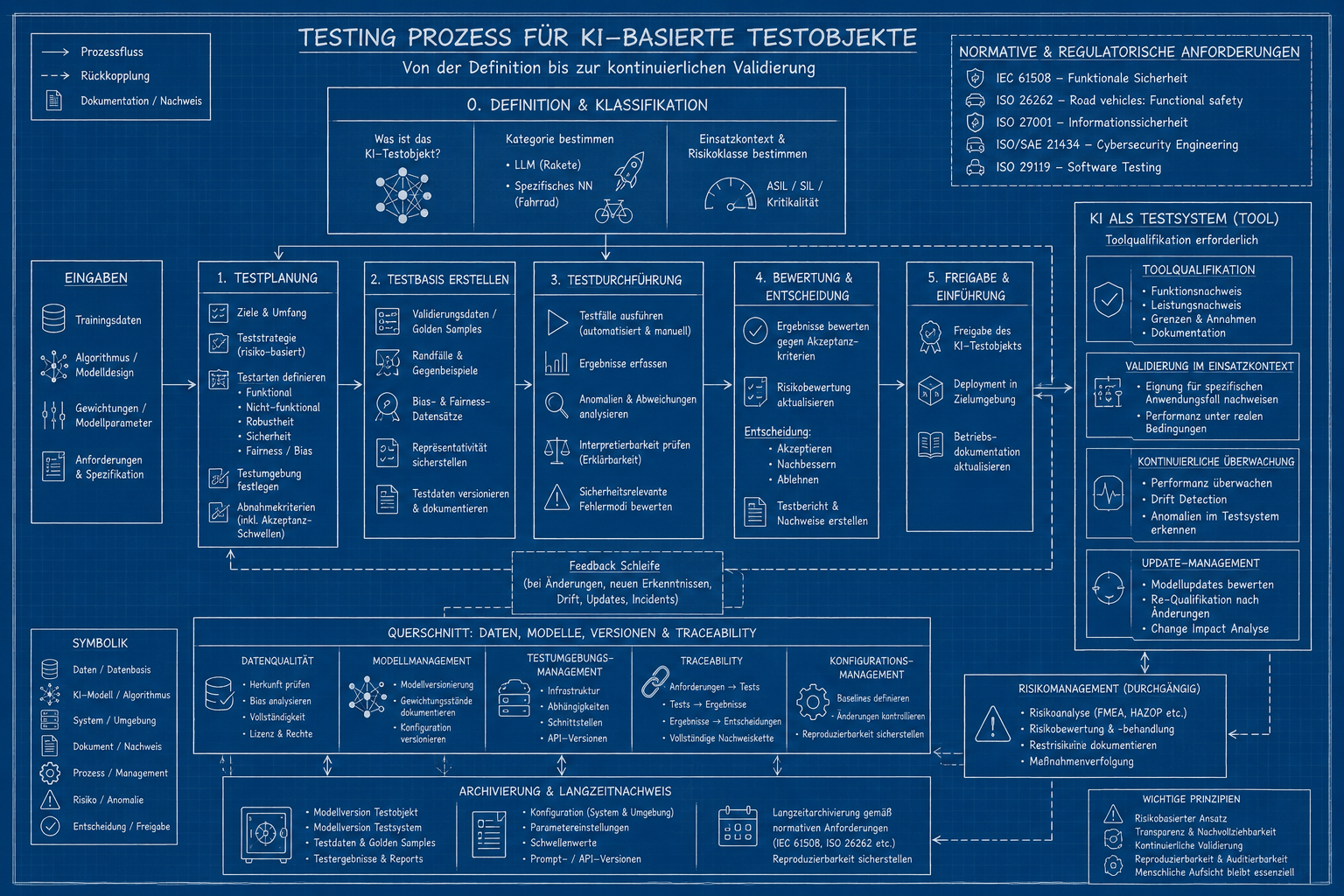
Teil 1: Die KI als Testobjekt – Rakete oder Fahrrad?
Wer KI-Produkte testen will, steht zunächst vor einer Taxonomie-Frage, die erstaunlich viele Tester schlicht ignorieren: Was ist das Ding eigentlich, das ich vor mir habe? Denn nicht jede KI ist gleich KI. Das ist ungefähr so, als würde man sagen: „Ich teste jetzt ein Fahrzeug“ – und meint dabei einmal ein Mountainbike und einmal eine Ariane-Trägerrakete. Beides bewegt sich fort. Die Gemeinsamkeiten enden dort.
Im Wesentlichen teilen sich KI-Systeme in zwei große Kategorien auf – und die haben unterschiedliche Implikationen für jede Teststrategie:
Large Language Models – die sprachbasierten Alleskönner, die Texte produzieren, zusammenfassen, übersetzen, halluzinieren und auf Anfrage auch Gedichte über Testnormen schreiben. Sie sind die Raketen. Diese Systeme arbeiten mit enormen Parametermengen, nichtlinearen Aktivierungsfunktionen und einem Ausgabeverhalten, das sich mit dem Begriff „vorhersehbar“ nur im weitesten Sinne des Wortes beschreiben lässt. Wenn Sie testen wollen, ob ein LLM konsistent antwortet, werden Sie feststellen: Es antwortet konsistent inkonsistent. Das ist kein Bug, das ist Feature. Dokumentieren Sie es entsprechend.
Hochspezifische neuronale Netze – etwa zur Bilderkennung, Anomalieerkennung oder Prozesssteuerung – verhalten sich dagegen deutlich deterministischer. Hier weiß man zumindest im Prinzip, was rein- und rausgeht. Hier haben wir also unsere „Fahrräder“. Was man nicht weiß, ist, warum genau das Modell zu diesem Ergebnis kommt. Willkommen beim Problem der Interpretierbarkeit, das seit Jahren erforscht wird und bei dem der Fortschritt ungefähr so schnell vonstatten geht wie die Rentenreform. Wer mehr zur KI-Effizienz-Debatte und dem, was Hersteller gerne verschweigen, wissen möchte, findet dazu erhellende Lektüre in unserem Buch „KI-Effizienz-Lüge“.
Was genau testen wir eigentlich?
Jetzt wird’s methodisch – und damit beginnt der Teil, bei dem Testingenieure entweder aufmerksam werden oder leise wegnicken. Ein KI-System besteht nicht aus einem monolithischen Block, den man mal kurz durchleuchtet. Es gibt mindestens vier Ebenen, auf denen sinnvolles Testen ansetzen kann – und muss:
Der Algorithmus: Die mathematische Grundstruktur des Modells. Backpropagation, Transformer-Architekturen, Convolutional Networks – je nachdem, was wir vor uns haben. Der Algorithmus selbst ist in der Regel das, was am stabilsten ist. Er ändert sich nicht jeden Dienstag. Schön. Testen kann man ihn trotzdem kaum isoliert, weil er ohne Gewichtungen so nützlich ist wie ein leeres Formular. Testergebnisse wären hier sogar eineindeutig und nachprüfbar.
Die Gewichtungen: Das ist das eigentliche „Wissen“ des Modells. Milliarden von Parametern, trainiert auf Daten, die wir hoffentlich kennen. Die Gewichtungen bestimmen das Verhalten. Sie sind das Ergebnis des Trainings. Und sie können sich ändern – durch Updates, durch Fine-Tuning, durch Continuous Learning. Wer sicherstellt, dass nach einem Gewichtsupdate das System noch das tut, was es soll, betreibt entweder sehr gutes Konfigurationsmanagement oder lebt in angenehmer Unkenntnis.
Die Trainingsdaten: Garbage in, garbage out – dieser Satz ist alt, aber er hat nichts von seiner Wahrheit verloren. Trainingsdaten bestimmen, was ein Modell kann, was es nicht kann und was es glaubt zu können, obwohl es das nicht kann. Letzteres ist besonders unterhaltsam. Testen der Trainingsdaten bedeutet: Herkunft prüfen, Bias analysieren, Repräsentativität bewerten, Lizenzkonflikte aufspüren. Das ist weniger Softwaretest als Quellenforschung mit juristischer Komponente.
Validierungsdaten / Golden Samples: Der klassische Testfall-Ansatz – nur dass er hier eine besondere Tücke hat. Was ist ein gültiger Testfall für ein LLM? Dass es auf „Wie alt ist die Erde?“ mit ca. 4,5 Milliarden Jahren antwortet? Gut. Und was, wenn es das kontext-abhängig mal anders formuliert? Auch gut? Noch gut? Diese Grenze festzulegen ist eine inhärent menschliche Aufgabe, die viele Testprozesse an ihre konzeptionellen Grenzen bringt. Wie tief KI dabei bereits in Infrastruktur und Prozesse eingedrungen ist, ohne dass wir es richtig bemerkt haben, zeigt sich beim näheren Hinsehen auf erschreckende Weise.
Teil 2: KI als Testsystem – wenn der Prüfer selbst geprüft werden muss
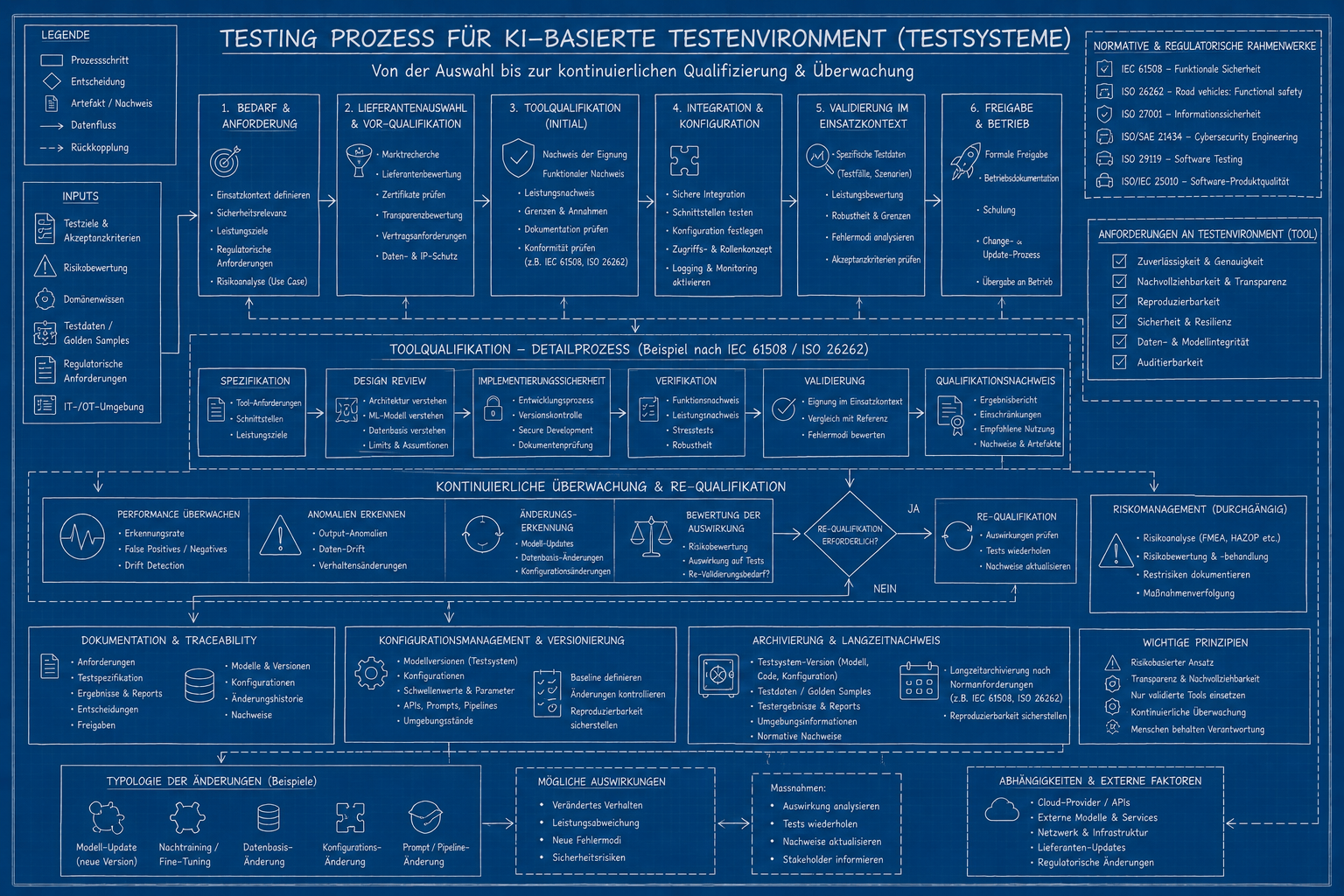
Nun drehen wir den Spieß um. KI wird nicht nur getestet – KI testet auch. Und das ist der Punkt, an dem Qualitätssicherungsabteilungen weltweit beginnen, in leicht panischem Ton Mails an ihre Normierungsausschüsse zu schreiben.
Denn wenn KI-Systeme als Testwerkzeuge eingesetzt werden – zum Beispiel zur automatisierten Bildauswertung in der Fertigung, zur Codeanalyse, zur Anomalieerkennung in Sicherheitssystemen – dann stellt sich unmittelbar die Frage der Toolqualifikation. Und hier kommen Normen ins Spiel, die man nicht ignorieren kann, auch wenn man sie gerne würde.
IEC 61508, ISO 26262 & Co.: Normen als ungebetene, aber notwendige Gäste
Die IEC 61508 ist die Mutter aller funktionalen Sicherheitsnormen. Sie regelt, wie sicherheitsbezogene Systeme entwickelt, betrieben und validiert werden müssen. Wer ein Testsystem einsetzt, das in sicherheitsrelevanten Kontexten Entscheidungen beeinflusst, muss dieses System qualifizieren. Das bedeutet: Nachweisen, dass das Werkzeug das tut, was es soll. Immer. Nicht meistens. Nicht „in 94,7 % der Fälle“. Immer.
Die ISO 26262 überträgt diesen Anspruch auf die Automobilindustrie. Wer also KI-basierte Testsysteme in der Fahrzeugentwicklung oder -prüfung einsetzt, bewegt sich in einem normativen Rahmen, der Toolqualifikation explizit vorschreibt – und der keinen Spaß versteht, wenn die Antwort auf „Warum glaubt das System, dass das Bremssystem in Ordnung ist?“ lautet: „Das Modell hat das halt so gelernt.“
Und dann ist da noch die Cybersecurity-Dimension. Die ISO 27001 und die ISO/SAE 21434 für automotive Cybersecurity stellen zusätzliche Anforderungen: Wer testet, muss auch sicherstellen, dass das Testsystem selbst kein Angriffspunkt ist. Ein KI-Testsystem, das sich manipulieren lässt, ist kein Sicherheitsnetz – es ist eine Einladung.
Die Qualifizierung des Testprozesses: Wer prüft den Prüfer?
Klassische Testprozesse haben eine gewisse Schönheit: Sie sind statisch, dokumentierbar, reproduzierbar. Man schreibt einen Testplan, führt Tests durch, vergleicht mit Soll-Werten, dokumentiert Abweichungen. Das Ganze ist linear, nachvollziehbar und in ISO 29119 geregelt wie ein Schweizer Uhrwerk.
KI-basierte Testsysteme zerstören diese Eleganz auf mehrfache Weise. Erstens: Das Modell kann sich ändern – durch Updates, durch Nachtraining, durch Drift. Ein Testsystem, das heute zuverlässig Fehler erkennt, kann morgen nach einem Modell-Update subtil andere Schwellenwerte anlegen, ohne dass irgendjemand explizit etwas konfiguriert hat. Das ist kein hypothetisches Szenario. Das passiert. Regelmäßig. Und es fällt oft erst auf, wenn es zu spät ist.
Zweitens: Die Qualifizierung des Updateprozesses ist konzeptionell noch weniger gelöst als die Qualifizierung des Systems selbst. Bei klassischer Software versteht man unter einem Update eine definierte, nachvollziehbare Änderung. Bei KI-Modellen ist ein Update oft das Ergebnis eines Trainings-Runs, dessen genaue Auswirkungen auf das Verhalten niemand vollständig vorhergesagt hat. Die fatale Tendenz von KI-Systemen, scheinbar nützliche Korrekturen vorzunehmen, die in Wahrheit neue Fehler einschmuggeln, ist kein Randphänomen – sie ist strukturell.
Das Zertifikat-Trugbild: Was der Lieferant bestätigt – und was er niemals kann
Hier beginnt einer der am häufigsten unterschätzten Stolpersteine in der gesamten KI-Testwelt – und gleichzeitig einer der gefährlichsten, weil er so einladend aussieht. KI-Lieferanten stellen Zertifikate und Konformitätsnachweise aus. ISO 9001, ISO/IEC 25010, interne Validierungsberichte, Model Cards, Safety Sheets – das Angebot ist vielfältig und die Dokumente sehen professionell aus. Manchmal sind sie es sogar.
Das Problem ist grundsätzlicher Natur: Was ein Lieferant zertifizieren kann, ist die allgemeine Eignung seines Modells – also dass es unter definierten Bedingungen, auf definierten Datensätzen, für definierte Aufgabenklassen eine bestimmte Leistung erbringt. Was er nicht zertifizieren kann, ist die Eignung für Ihren spezifischen Testanwendungsfall. Denn die ergibt sich aus dem Kontext – und der liegt beim Anwender, nicht beim Hersteller. Die Cruix dabei – Kompetenz in KI-Fragen.
Ein Beispiel: Ein Bilderkennungsmodell ist zertifiziert für die Erkennung von Oberflächendefekten auf Metallplatten mit einer Fehlerrate unter 0,1 %. Das klingt beeindruckend. Jetzt setzt man es in einer Testumgebung ein, in der Beleuchtungsbedingungen variieren, Teile aus einem anderen Material stammen und die Defektklassen leicht anders definiert sind als im Trainingsset. Hat das Zertifikat noch Aussagekraft? Formal ja. Praktisch: deutlich weniger als der Einkaufsabteilung lieb wäre.
Diese strukturelle Lücke zwischen Lieferanteneignung, Tooleignung und Anwendungseignung erzeugt ein handfestes Problem in der Nachweiskette. Denn wer in einem regulierten Umfeld – Medizintechnik, Automotive, Luftfahrt, industrielle Sicherheit – den Nachweis führen muss, dass sein Testsystem geeignet ist, kann sich nicht auf das Zertifikat des Lieferanten stützen. Er muss die Eignung selbst nachweisen, durch eigene Validierung, eigene Testdaten, eigene Bewertung der Performanz unter realen Einsatzbedingungen. Das ist kein bürokratischer Reflex – das ist die logische Konsequenz daraus, dass Kontext nicht delegierbar ist.
Was in der Praxis häufig passiert, ist das Gegenteil: Man kauft ein KI-Testsystem, erhält ein Zertifikat, heftet es in den Qualitätssicherungsordner und betrachtet die Sache als erledigt. Audit-sicher ist das, solange niemand genauer hinschaut. In einem ernsthaften Compliance-Review oder gar einem Schadensfall wird diese Nachweislücke sichtbar – und dann ist das Zertifikat, das so beruhigend aussah, ungefähr so hilfreich wie ein Regenschirm aus Papier.
Besonders brisant wird das im Kontext der IEC 61508 und der ISO 26262, die explizit verlangen, dass Testwerkzeuge für den spezifischen Einsatzkontext qualifiziert sein müssen – tool qualification ist kein optionales Beiwerk, sondern normative Anforderung. Was der Lieferant dazu beitragen kann, ist Dokumentation über das Modell, Beschreibungen der Grenzen, Angaben zur Trainingsdatenbasis. Was er nicht liefern kann: den Eignungsnachweis für Ihren Use-Case. Den müssen Sie selbst erbringen. Mit Ihren Daten. Unter Ihren Bedingungen. Und das kostet Zeit, Aufwand und methodisches Denken – drei Ressourcen, die in Projektzeitplänen erfahrungsgemäß gut versteckt sind.
Die ehrliche Empfehlung lautet daher: Zertifikate vom KI-Lieferanten entgegennehmen, sorgfältig lesen – und dann verstehen, was sie nicht aussagen. Anschließend den eigenen Eignungsnachweis als eigenständige Aufgabe planen, budgetieren und dokumentieren. Wer das als lästige Zusatzarbeit betrachtet, hat die Grundlogik von Toolqualifikation noch nicht ganz verinnerlicht. Wer es als normalen Teil des Prozesses begreift, hat zumindest eine realistische Chance, im Audit nicht schweißgebadet aufzuwachen.
Testabdeckung: Das 100%-Ziel als Wunschdenken
In der klassischen Softwareentwicklung ist 100 % Codeabdeckung ein ehrgeiziges, aber zumindest theoretisch erreichbares Ziel. Man kann jeden Pfad durch ein Programm definieren, schreiben, testen. Bei KI-Systemen ist dieses Ziel nicht nur schwer – es ist prinzipiell illusorisch. Und wer das zu laut sagt, bekommt merkwürdige Blicke in Auditgesprächen.
Der Eingaberaum eines Large Language Models ist praktisch unendlich. Selbst ein hochspezifisches neuronales Netz zur Bilderkennung arbeitet in einem Parameterraum, der vollständiges Testen strukturell ausschließt. Man kann Repräsentativität anstreben. Man kann Risikoklassen bilden, priorisieren, mit Golden Samples arbeiten. Aber 100 % Testabdeckung im KI-Kontext anzustreben ist so, als würde man versuchen, alle möglichen Gesichtsausdrücke eines Menschen zu fotografieren. Theoretisch vorstellbar, praktisch nicht zu Ende zu denken.
Was bleibt, ist eine ehrliche Risikostrategie: Welche Bereiche sind sicherheitsrelevant? Welche Fehlermodi sind kritisch? Wo brauche ich besonders dichte Testabdeckung? Und – wichtig – wo akzeptiere ich bewusst Lücken und dokumentiere, warum? Das ist weniger glamourös als „100 % Coverage“, führt aber zu ehrlicheren Aussagen über Systemverhalten.
Teil 3: KI denkt außerhalb der Physik – Vorteil oder Albtraum?
Hier wird es philosophisch – und das ist im Kontext von Testing keine Schwäche, sondern eine Notwendigkeit. Denn KI-Systeme haben eine Eigenschaft, die klassische Testsysteme nicht haben: Sie sind nicht an menschliche Erfahrungswerte gebunden.
Das klingt zunächst wie ein Vorteil. Und das ist es auch. Ein KI-basiertes Testsystem kann Anomalien erkennen, die kein menschlicher Tester je aufgefallen wären, weil kein Mensch je auf die Idee gekommen wäre, dort zu suchen. Es kann Musterkombinationen analysieren, die jenseits menschlicher Intuitionen liegen. Es kann – im besten Fall – blinde Flecken im Testprozess aufdecken, die seit Jahren unentdeckt geblieben sind.
Gleichzeitig ist genau diese Eigenschaft auch die größte Quelle von Verwirrung, Misstrauen und Fehlinterpretation. Denn wenn ein KI-System eine Anomalie meldet, die kein Mensch als solche erkennt, stehen Testingenieure vor einem epistemischen Dilemma: Glauben wir der Maschine oder unserer Erfahrung? Das ist keine rhetorische Frage. Sie stellt sich täglich in realen Testumgebungen. Und die Antwort hängt davon ab, wie gut das Testsystem validiert wurde – was uns wieder zurück zu den Normen führt, die wir oben erwähnt haben.
Das Außerhalb-der-Physik-Denken ist also kein Freifahrtschein. Es ist eine Fähigkeit, die methodisch eingebettet sein muss. KI, die Anomalien erkennt, die niemand versteht, ist nur dann wertvoll, wenn es Prozesse gibt, mit denen man diese Erkenntnisse validieren, interpretieren und – falls nötig – verwerfen kann. Ohne diese Rückkopplungsschleife ist die Überlegenheit der Maschine ein Rauschen, das niemand decodieren kann.
Dazu kommt: KI-Systeme produzieren im Kontext sicherheitsrelevanter Tests manchmal Ergebnisse, die physikalisch oder technologisch nicht plausibel erscheinen – nicht weil sie falsch sind, sondern weil sie jenseits bekannter Erfahrungswerte liegen. Das ist kein Argument gegen KI-Testsysteme. Es ist ein Argument dafür, dass die Menschen, die diese Systeme betreiben, sehr genau verstehen müssen, was sie tun – und was nicht. Dabei muss die Expertise über das klassischen Testerwissen nach ISTQB deutlich hinausgehen und sowohl Inhalte der Künstlichen Intelligenz, Physik aber auch – auch wenn es komisch klingt – Philosophie beherrschen.
Teil 4: Die neue organisatorische Realität – Wenn der Test das Dorf verlässt
Es gab eine Zeit, in der Testumgebungen überschaubar waren. Sie standen in einem Raum. Manchmal in zwei Räumen. Die Verantwortlichkeiten waren klar. Der Testingenieur kannte seine Umgebung, seine Werkzeuge, seine Supplier. Wenn etwas schiefging, wusste man in der Regel, wo man anfangen musste zu suchen.
Diese Zeit ist vorbei.
KI-basierte Testsysteme bringen eine fundamentale organisatorische Verschiebung mit sich: Die Testumgebung ist nicht mehr lokal. Sie ist nicht mehr vollständig unter Kontrolle der Organisation, die testet. Sie hängt von externen Modellen, Cloud-Diensten, API-Schnittstellen und – das wird gerne vergessen – von den Update-Zyklen externer Anbieter ab.
Wenn ein Anbieter sein Modell aktualisiert, verändert sich potenziell das Verhalten des Testsystems. Ohne Ankündigung. Ohne Changelog, der ausreicht, um Auswirkungen auf die Testabdeckung zu beurteilen. Das ist ein Kontrollverlust, der in klassischen Qualitätsmanagementsystemen so nicht vorgesehen ist – und den die einschlägigen Normen noch lernen müssen, adäquat zu adressieren. Wie tiefgreifend externe KI-Infrastruktur bereits in digitale Systeme eingebettet ist und welche strukturellen Risiken das erzeugt, ist ein Thema, das wir auf 42thinking bereits ausführlich beleuchtet haben.
Hinzu kommen neue Lieferantenbeziehungen, die klassische Qualification-Flows ad absurdum führen können. Wer haftet, wenn ein externes KI-Modell, das als Testsystem qualifiziert wurde, nach einem Update falsche Testergebnisse produziert? Der Hersteller? Der Integrator? Der Anwender? Die Antwort auf diese Frage ist, vorsichtig ausgedrückt, noch nicht vollständig ausdiskutiert. Weniger vorsichtig ausgedrückt: Niemand weiß es genau, und das sollte uns alle ein bisschen beunruhigen.
Die organisatorische Konsequenz ist klar, auch wenn sie schwer umzusetzen ist: Wer KI als Testsystem einsetzt, muss Supplier-Management, Update-Governance und Continuous Validation als integrierte Prozesse denken – nicht als nachgelagerte Aufgaben. Das bedeutet mehr Koordinationsaufwand, mehr Schnittstellen, mehr Dokumentation. Aber auch: mehr Ehrlichkeit darüber, wie viel Kontrolle man tatsächlich hat – und wie viel man schlicht delegiert hat, ohne es zu merken.
Wer glaubt, dass das ein Problem ist, das nur große Konzerne betrifft, irrt sich. Auch mittelständische Unternehmen setzen zunehmend KI-basierte Testwerkzeuge ein – oft ohne vollständigen Überblick über die normativen Implikationen. Und während die Qualitätsabteilung noch überlegt, wie man ein klassisches Testsystem qualifiziert, hat die IT-Abteilung bereits das nächste Modell-Update eingespielt. Das ist kein Einzelfall. Das ist der Normalzustand.
Teil 4b: Archivierung – Hat das eigentlich jemand zu Ende gedacht?
An dieser Stelle muss eine Frage gestellt werden, die in den meisten KI-Projektmeetings nicht vorkommt – vermutlich weil die Antwort unbequem ist und das Catering schon weggeräumt wurde: Hat eigentlich jemand über die Archivierung von KI-basierten Testsystemen nachgedacht?
Normen wie die IEC 61508, die ISO 26262 oder auch branchenspezifische Varianten aus Medizintechnik und Luftfahrt fordern, dass Testsysteme, Testergebnisse und die Konfiguration der Testumgebung zum Zeitpunkt der Prüfung reproduzierbar und langfristig nachvollziehbar archiviert werden. Der Gedanke dahinter ist simpel: Wenn in fünf, zehn oder zwanzig Jahren jemand wissen will, unter welchen Bedingungen ein Produkt als sicher freigegeben wurde, soll das nachvollziehbar sein. Revisionen, Zulassungsaudits, Schadensfälle – sie alle setzen voraus, dass man sagen kann: Dieses System wurde mit dieser Testkonfiguration unter diesen Bedingungen geprüft.
Mit klassischer Testsoftware war das lösbar. Man archivierte die Toolversion, die Konfigurationsdatei, die Testergebnisse, stellt den HIL in den Keller. Versioniert, signiert, weggelegt. Fertig. Lästig, aber handhabbar.
Jetzt kommt KI – und das Konzept beginnt, auf eine Weise zu bröckeln, die man nur als strukturelle Archivierungskatastrophe beschreiben kann.
Das Versions-Mückenproblem
KI-Modelle haben Versionen. Viele Versionen. Manche Anbieter rollen Updates nicht in diskreten Releases aus, sondern kontinuierlich – über API-Endpunkte, die heute Version 3.7 ausliefern und morgen 3.8, ohne dass der Aufrufer zwingend eine Benachrichtigung bekommt, ohne dass sich die Schnittstelle verändert, ohne dass ein Changelog existiert, der für Auditzwecke ausreichend wäre. Das ist, um im Bild zu bleiben, ungefähr so, als würde man ein Messgerät kalibrieren lassen und der Kalibrierdienst tauscht still die Referenzgewichte aus, ohne das Kalibrierzertifikat zu aktualisieren.
Die Frage, die sich daraus ergibt, ist keine akademische: Welche Modellversion hat welchen Test durchgeführt? Und kann ich das in drei Jahren noch nachweisen? Und wurde das getestete Objekt – also das KI-System, das ich geprüft habe – ebenfalls in einer archivierbaren Version eingefroren? Oder hat auch das Testobjekt zwischen zwei Testläufen still ein Update erhalten?
Man beachte: Das Problem trifft gleichzeitig beide Seiten des Prozesses. Das Testobjekt – also das KI-System, das geprüft wird – kann sich zwischen Testläufen verändern. Die Testumgebung – also das KI-System, das prüft – kann sich ebenfalls verändern. Im schlimmsten Fall ändern sich beide gleichzeitig, in unbekannten Richtungen, ohne synchronisierten Changelog. Was dann dokumentiert wird, ist ein Testergebnis, das exakt so reproduzierbar ist wie ein Foto eines Wolkenformations-Verlaufs: interessant, einmalig, nicht wiederholbar.
Was Normen fordern – und was die Realität liefert
Normen sprechen in diesem Zusammenhang von Configuration Management und Traceability. Beides klingt bürokratisch und ist es auch ein bisschen – aber aus gutem Grund. Traceability bedeutet: Ich kann zu jedem Testergebnis sagen, welche Version des Prüflings unter welcher Version des Testsystems mit welchen Testdaten geprüft wurde. Configuration Management bedeutet: Ich kann diesen Zustand rekonstruieren oder zumindest vollständig beschreiben.
Bei KI-Systemen sind beide Anforderungen strukturell schwerer zu erfüllen als bei klassischer Software – und in manchen Cloud-basierten Szenarien faktisch nicht erfüllbar ohne aktives Gegensteuern. Wer über eine API auf ein extern gehostetes Modell testet, das der Anbieter jederzeit aktualisieren kann, hat kein Configuration Management. Er hat eine Hoffnung.
Die Anforderung, Testergebnisse versioniert zu dokumentieren, gewinnt unter diesen Bedingungen eine neue Dimension. Es reicht nicht mehr, das Ergebnis selbst zu archivieren. Archiviert werden muss der vollständige Zustand des Systems zum Testzeitpunkt: Modellversion Testobjekt, Modellversion Testumgebung, Promptversion falls relevant, Datenbasis, Schwellenwerte, Konfigurationsparameter, API-Endpunktversion – und idealerweise ein Nachweis darüber, dass diese Parameter zum Zeitpunkt des Tests tatsächlich so vorlagen und nicht nachträglich rekonstruiert wurden. Das ist kein Aufwand mehr, den man nebenbei erledigt. Das ist ein eigenständiger Prozess, der entworfen, implementiert und gepflegt werden will.
Einfrieren als Lösungsansatz – und seine Grenzen
Die naheliegende Lösung lautet: Modelle einfrieren. Keine automatischen Updates in produktiven Testumgebungen. Versionierte Snapshots statt rollender Releases. Das ist technisch möglich, zumindest bei Modellen, die lokal oder in kontrollierten Umgebungen betrieben werden. Es hat allerdings einen Haken, der in Verkaufspräsentationen von KI-Anbietern auffälligerweise nicht vorkommt: Ein eingefrorenes Modell verbessert sich nicht. Und bei KI-Systemen, gerade im Bereich Anomalieerkennung oder Qualitätsprüfung, ist die Verbesserung durch kontinuierliches Lernen oft ein zentrales Verkaufsargument.
Man steht also vor einer echten Zielkonfliktsituation: Entweder archivierungsfähige Stabilität – oder kontinuierliche Verbesserung. Beides gleichzeitig ist, zumindest mit den heute verfügbaren Prozessen und Normen, schwer zu haben. Wer das auflösen will, braucht mindestens einen definierten Release-Prozess mit expliziter Re-Qualifizierung nach jedem Modell-Update – was den Vorteil der Kontinuierlichkeit erheblich relativiert und den Aufwand auf ein Niveau hebt, das Projektleiter zum Schweigen bringt.
Das ist kein Argument gegen KI in Testsystemen. Es ist ein Argument dafür, diese Fragen vor der Beschaffungsentscheidung zu stellen – und nicht erst dann, wenn der erste externe Auditor mit dem Finger auf die Versionsdokumentation zeigt und eine Augenbraue hebt.
Wer sich fragt, wie tief das Problem geht: die schleichende, kaum sichtbare Integration von KI in Infrastrukturen, die eigentlich kontrolliert sein sollten, ist kein isoliertes Archivierungsproblem. Es ist das Symptom einer Technologiewelle, die schneller rollt als die Governance-Strukturen, die sie begleiten müssten.
Fazit: Testen in der KI-Ära bedeutet Denken in neuen Kategorien
Die Frage, ob KI Testobjekt oder Testenvironment ist, lässt sich nicht mit einem binären Entweder-oder beantworten. In der Praxis ist sie oft beides – manchmal gleichzeitig, manchmal in Abhängigkeit, immer mit normativen Implikationen, die man nicht ignorieren sollte.
Was sich klar sagen lässt: Wer KI-Systeme mit klassischen Testmethoden testen will, ohne die zugrundeliegenden konzeptionellen Unterschiede zu verstehen, wird scheitern. Nicht dramatisch, nicht sofort – sondern schleichend, mit kleinen Unschärfen, die sich kumulieren, bis irgendwann ein System als validiert gilt, das es nicht ist.
Und wer KI als Testsystem einsetzt, ohne Toolqualifikation, Update-Governance und organisatorische Abhängigkeiten mitgedacht zu haben, betreibt Qualitätssicherung auf Hoffnungsbasis. Das mag in manchen Kontexten ausreichen. In sicherheitsrelevanten Domänen tut es das nicht.
Die gute Nachricht: Die Konzepte, die hier gebraucht werden, sind nicht neu. Risikobasiertes Testen, Konfigurationsmanagement, Supplier-Qualifikation, Continuous Validation – all das existiert bereits. Es muss nur konsequent auf die neue Realität angewendet werden. Und dazu braucht es vor allem eines: das ehrliche Eingeständnis, dass KI-Systeme andere Anforderungen an das Testing stellen als klassische Software. Nicht mehr, nicht weniger.
Wer diesen Schritt gemacht hat, hat bereits einen erheblichen Vorsprung gegenüber denjenigen, die noch überlegen, ob man das alles nicht mit einem etwas längeren Testplan lösen kann.
Spoiler: Kann man nicht.
Weiterführend empfehlenswert:
- „KI-Effizienz-Lüge“ – unser Buch zu den blinden Flecken in KI-Versprechen
- KI als digitaler Schiffsbohrwurm – wie KI unbemerkt Systeme verändert
- Autokorrektur: Wenn KI still und leise korrigiert, was gar nicht falsch war
- Alle Bücher von 42thinking
- IEC 61508 – Funktionale Sicherheit elektrischer/elektronischer/programmierbarer elektronischer Systeme
- ISO 26262 – Road vehicles: Functional safety
- ISO/SAE 21434 – Road vehicles: Cybersecurity engineering